
Revenue
$3.40M
2023
Valuation
$3.60B
2023
Funding
$901.13M
2024
Revenue
Groq has a significant cost advantage in silicon/chip manufacturing compared to Nvidia.
Groq's wafer costs are estimated at <$6,000 on 14nm, while Nvidia's H100 wafers on 5nm cost ~$16,000 plus expensive HBM memory.
Groq's simpler architecture and lack of external memory result in a raw silicon BOM cost per token that is 70% lower than a latency-optimized Nvidia system.
However, Groq requires vastly more chips (576 vs 8) and incurs much higher system level costs (personnel, power, rack space) to deliver a complete inference unit. When accounting for these full costs, Groq's TCO advantage for latency-optimized inference narrows to ~40%.
As Groq moves to 4nm chips in 2025, their cost advantages may expand further. But they will need significant capital to fund the development and production, while Nvidia is rapidly innovating with their next-gen H100 successor.
Valuation
Groq is valued at $2.8B as of their $640M funding round in August 2024, led by BlackRock Inc. funds and Cisco Systems Inc.'s investment arm.
Groq has raised over $1B in total funding. The latest August 2024 round saw participation from major investors including BlackRock, Cisco Systems, and Samsung Electronics' investment arm, alongside Tiger Global and D1 Capital Partners.
Product

Groq is a silicon company founded in 2016 by Jonathan Ross, the lead architect behind Google's Tensor Processing Unit (TPU).
Their core product is the Groq Tensor Streaming Processor (TSP), a custom AI accelerator chip designed specifically for high-performance, low-latency inference on large language models and other AI workloads.
Groq's chip has market-leading inference performance of over 500-700 tokens/second on large language models—a 5-10x improvement over Nvidia's latest data center GPUs.
Groq provides access to its TSP infrastructure through GroqCloud, a cloud service that allows developers to run large language models like Llama at unprecedented speeds via an API.
The company has also announced plans for on-prem enterprise deployments.
By optimizing for the inference workload through a ground-up hardware/software co-design, Groq aims to become the premier platform for real-time, low-latency AI use cases that are challenging for current GPU-based solutions.
Business Model
At a high level, Groq operates a hybrid business model combining elements of semiconductors, cloud services, and on-premise enterprise deployments. However, their core product offering revolves around their custom AI accelerator chip, the Tensor Streaming Processor (TSP), optimized for ultra-low latency inference on large language models.
Cloud services
Groq's most visible revenue stream currently comes from GroqCloud, their cloud AI inference platform. GroqCloud provides access to Groq's massively parallel TSP infrastructure running the latest large language models like Llama and Mistral MixedRoll through a simple pay-as-you-go API. This operates similar to the Nvidia-hosted AI services from major cloud providers.
Groq charges extremely aggressive pricing on GroqCloud starting at $0.27 per million tokens generated. While likely unprofitable currently, this pricing helps drive adoption of their TSP chips by making it easy for developers to experiment and build apps/services on Groq's unique low-latency architecture.
Semiconductors
The other side of Groq's business involves selling their TSP chips and servers directly to enterprises with large on-premise AI infrastructure needs. Given Groq's nascent stage, this revenue stream is likely still modest.
However, selling hardware deployments could become a bigger revenue driver over time as more organizations want the flexibility and data security of running large language models internally. Groq has announced on-prem deployments with entities like Saudi Aramco.
Similar to traditional semiconductor companies, Groq likely charges a upfront fee to purchase the TSP chips/servers, with potential for ongoing support/maintenance revenues.
Competition
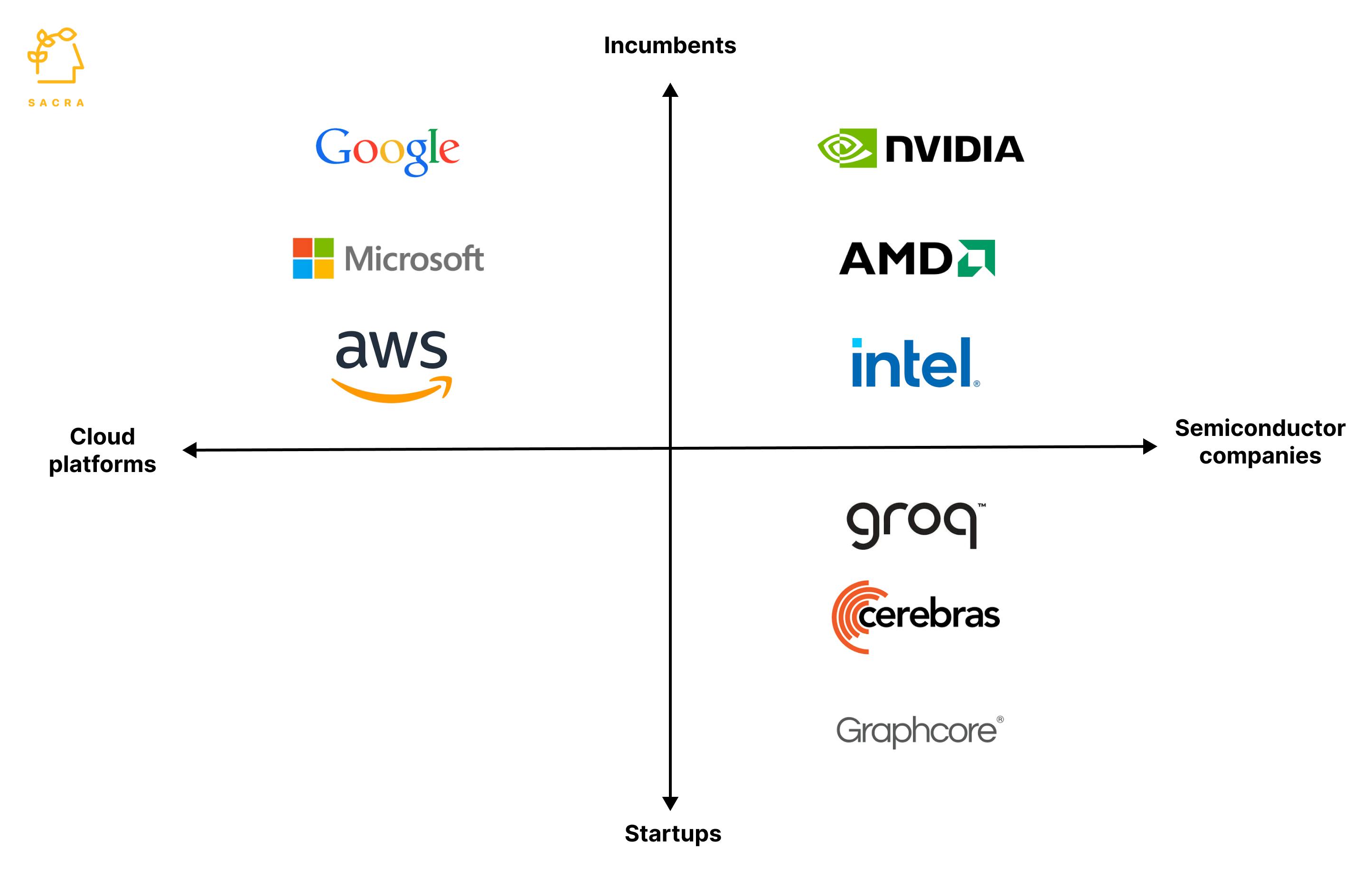
Groq is up against three basic categories of competition: silicon incumbents, hyperscaler clouds, and other startups.
Incumbents
Even though more than 50 companies are making AI chips, the AI data center chip market is dominated by three companies, Nvidia ($390B), Intel ($123B), and AMD ($118B).
Nvidia used its GPUs, built primarily for gaming, to capture nearly 100% share of the AI training market early on, growing its market cap from $7B to $3.25T in less than ten years. However, Nvidia's GPU architecture seems to face some inherent limitations for ultra-low latency inference required for interactive AI applications.
Cloud platforms
The major public cloud providers all have active AI accelerator programs leveraging their hyperscale economics and co-design capabilities. Google has been deploying its Tensor Processing Units (TPUs) since 2015, while AWS recently released its Inferentia chip focused on inference. Microsoft has utilized FPGAs extensively and has its own pipeline of AI chips in development.
These cloud platforms can package their custom silicon into optimized "AI boxes" and leverage their distribution capabilities - potentially squeezing out current chip suppliers in 5-10 years if they achieve cost/performance leadership.
Startups
2021 alone saw AI chip startups raise over $10B in VC funding as investors piled into the next potential "arm" wave of novel AI architectures. Well-funded startups like Cerebras ($5B+ valuation) with its massive chip aimed at training, and Graphcore have gained traction at prominent research centers.
However, none have broken through to challenge Nvidia's dominance of the training market yet. For inference, Groq is taking an innovative architectural approach tailored for low-latency applications, but remains an emerging player with an unproven long-term business model.
Groq's proprietary low-latency architecture gives it differentiation versus Nvidia's CUDA ecosystem, but also diminishes its addressable market compared to accelerators optimized for throughput over latency. Sustaining long-term differentiation as larger competitors enhance their offerings will be critical for Groq to maintain a viable competitive positioning.
TAM Expansion
Groq's initial TAM is centered around the market for AI inference acceleration, with a specialized focus on latency-sensitive workloads like large language model deployment, conversational AI, and autonomous systems.
The size of the overall AI inference acceleration market was estimated at $12B in 2022 and has been projected to grow to $83B by 2027.
However, only a subset of these inference workloads are truly latency-sensitive enough to favor Groq's architecture over throughput-optimized accelerators
Based on industry analysis, we estimate Groq's immediately addressable inference acceleration TAM focused on extremely low-latency requirements is likely in the range of $3-5B but growing rapidly.
While starting in a niche, Groq has clear opportunities to expand its addressable market if it can extend its architectural advantages:
Hardware iterations
Planned moves to denser process nodes (e.g. 4nm roadmap) could improve chip economics to better compete on throughput and capture a wider range of inference use cases outside the latency niche.
Software/ML model co-design
Working directly with AI research labs and model developers, Groq could optimize future models and systems to take maximum advantage of their massively parallel/scaled-out architecture.
New accelerated computing apps
Novel applications like real-time AI agents, autonomous systems, coding assistants, etc. could drive demand for more interactive, latency-optimized AI compute.
Funding Rounds
|
|
||||||||||||
|
||||||||||||
|
|
||||||||||||
|
||||||||||||
|
|
||||||||||||
|
||||||||||||
|
|
||||||||||||
|
||||||||||||
| View the source Certificate of Incorporation copy. |
News
DISCLAIMERS
This report is for information purposes only and is not to be used or considered as an offer or the solicitation of an offer to sell or to buy or subscribe for securities or other financial instruments. Nothing in this report constitutes investment, legal, accounting or tax advice or a representation that any investment or strategy is suitable or appropriate to your individual circumstances or otherwise constitutes a personal trade recommendation to you.
This research report has been prepared solely by Sacra and should not be considered a product of any person or entity that makes such report available, if any.
Information and opinions presented in the sections of the report were obtained or derived from sources Sacra believes are reliable, but Sacra makes no representation as to their accuracy or completeness. Past performance should not be taken as an indication or guarantee of future performance, and no representation or warranty, express or implied, is made regarding future performance. Information, opinions and estimates contained in this report reflect a determination at its original date of publication by Sacra and are subject to change without notice.
Sacra accepts no liability for loss arising from the use of the material presented in this report, except that this exclusion of liability does not apply to the extent that liability arises under specific statutes or regulations applicable to Sacra. Sacra may have issued, and may in the future issue, other reports that are inconsistent with, and reach different conclusions from, the information presented in this report. Those reports reflect different assumptions, views and analytical methods of the analysts who prepared them and Sacra is under no obligation to ensure that such other reports are brought to the attention of any recipient of this report.
All rights reserved. All material presented in this report, unless specifically indicated otherwise is under copyright to Sacra. Sacra reserves any and all intellectual property rights in the report. All trademarks, service marks and logos used in this report are trademarks or service marks or registered trademarks or service marks of Sacra. Any modification, copying, displaying, distributing, transmitting, publishing, licensing, creating derivative works from, or selling any report is strictly prohibited. None of the material, nor its content, nor any copy of it, may be altered in any way, transmitted to, copied or distributed to any other party, without the prior express written permission of Sacra. Any unauthorized duplication, redistribution or disclosure of this report will result in prosecution.