
Revenue
$200.00M
2024
Valuation
$3.50B
2024
Growth Rate (y/y)
100%
2024
Funding
$600.00M
2024
Revenue
Sacra estimates that Cribl reached $200M in annual recurring revenue (ARR) in 2024, up 71% YoY from $117M ARR at the end of 2023, valued at $3.5B as of their August 2024 Series E for a 17.5x revenue multiple.
Compare to Datadog (NASDAQ: DDOG) at $2.53B in trailing twelve months revenue (TTM), up 19% YoY, valued at $51.6B for a 20.4x multiple, Elastic (NYSE: ESTC) at $1.37B TTM revenue, up 13% YoY, valued at $12B for a 8.8x multiple, and Splunk (NYSE: CSCO) at $4.7B in annual recurring revenue (ARR), up 10% YoY, accounting for 20% of Cisco’s total product revenue after their acquisition closed in March.
Cribl's growth is driven by its data pipeline products that help enterprises reduce spending on platforms like Splunk by 30-90%. The company typically charges around $500K annually for 5TB of daily data ingest, positioning itself to save customers millions in data management costs.
The company maintains a strong 145% net revenue retention rate and counts 43 Fortune 100 companies among its customers, with 25% of the Fortune 500 using its solutions. Enterprise customers are particularly drawn to Cribl's vendor-neutral approach and cost-saving capabilities in managing rapidly growing data volumes.
Following a $319M Series E round in August 2024, Cribl achieved a $3.5B valuation, implying a 17.5x revenue multiple. While not yet cash-flow positive, the company aims to achieve this milestone in 2025 while maintaining its strong growth trajectory. Cribl's cloud business represents over 30% of revenue, expected to reach 40-50% in the coming years.
Valuation
Cribl reached a $3.5B valuation in August 2024 following a $319M Series E funding round, representing a 40% increase from its Series D valuation in 2022. The company has raised a total of $600M since its founding in 2018, with key investors including GV (Google Ventures), GIC, CapitalG, IVP, and CRV.
As of January 2025, Cribl reported $200M in annual recurring revenue (ARR), implying a 17.5x revenue multiple at its current valuation.
GV's investment in the Series E round was noted as one of their largest in their 15-year history, with GV General Partner Michael McBride joining Cribl's board.
Product
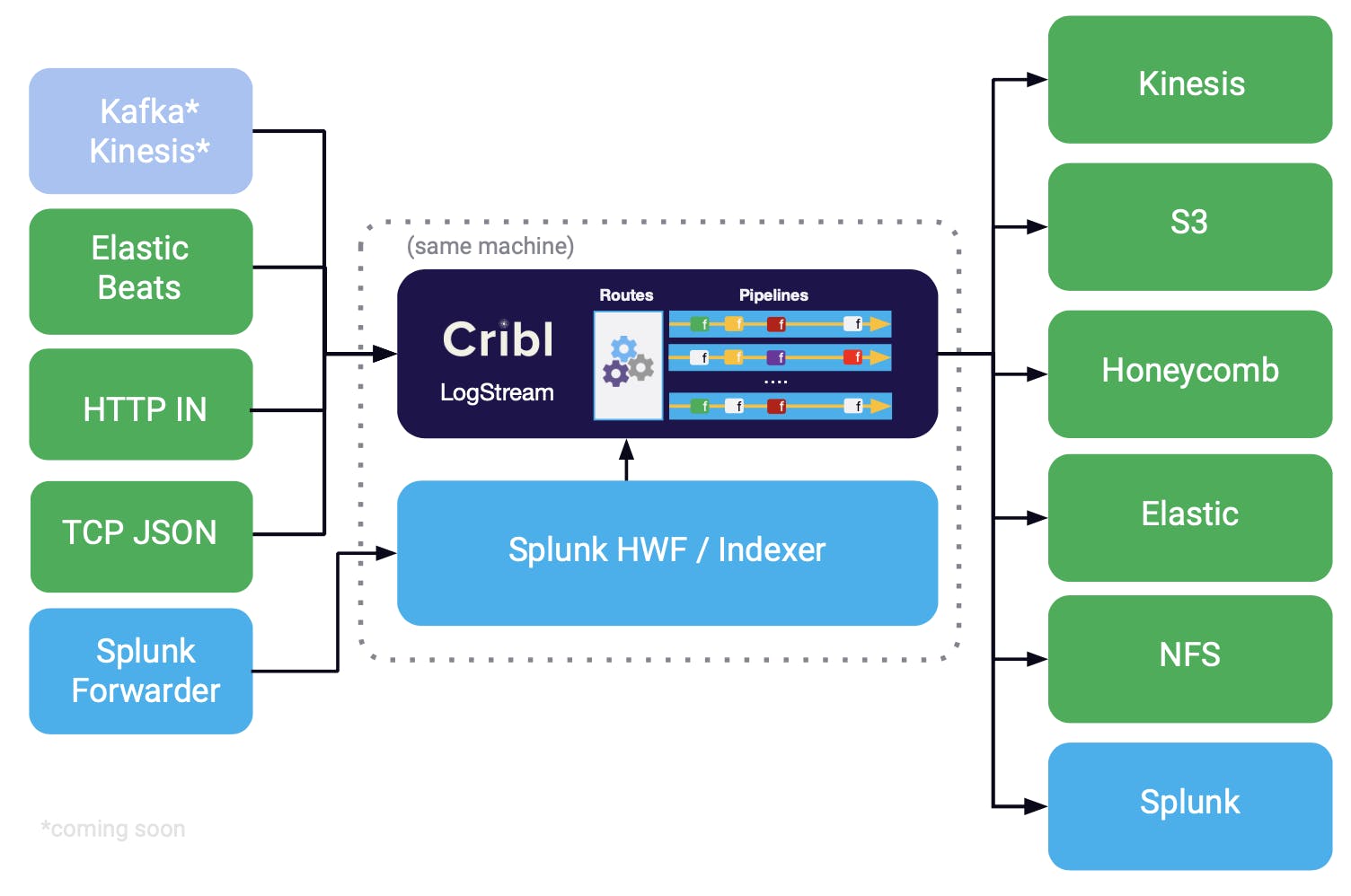
Cribl was founded in 2018 by former Splunk employees, including Clint Sharp, with the vision of creating a vendor-neutral data management solution for IT and security teams.
Cribl found product-market fit as a data pipeline solution for large enterprises struggling to manage growing volumes of IT and security telemetry data. Their initial product, Cribl Stream, allowed organizations to route, filter, and process data before sending it to various analysis and storage destinations.
The core technology enables IT and security teams to collect data from any source, transform it as needed, and send it to any destination while maintaining complete control over the data's format and storage location. For example, a security team can collect logs from various systems, filter out unnecessary information, and route critical security events to their SIEM while sending complete data to cheaper storage for compliance purposes.
After launching as a data router that helps companies save money on data stored in Splunk, Cribl in 2024 vertically integrated backwards into building its own data storage offering—Cribl Lake—that lets IT teams store petabytes of telemetry data at lower costs while maintaining searchability. With Cribl Lake, Cribl is continuing its strategy of attacking and counter-positioning against the incumbents’ cash cow business model of monetizing on data volume, both trimming the total volume of data that must be stored and offering up to 1TB of daily data ingestion for free.
Business Model
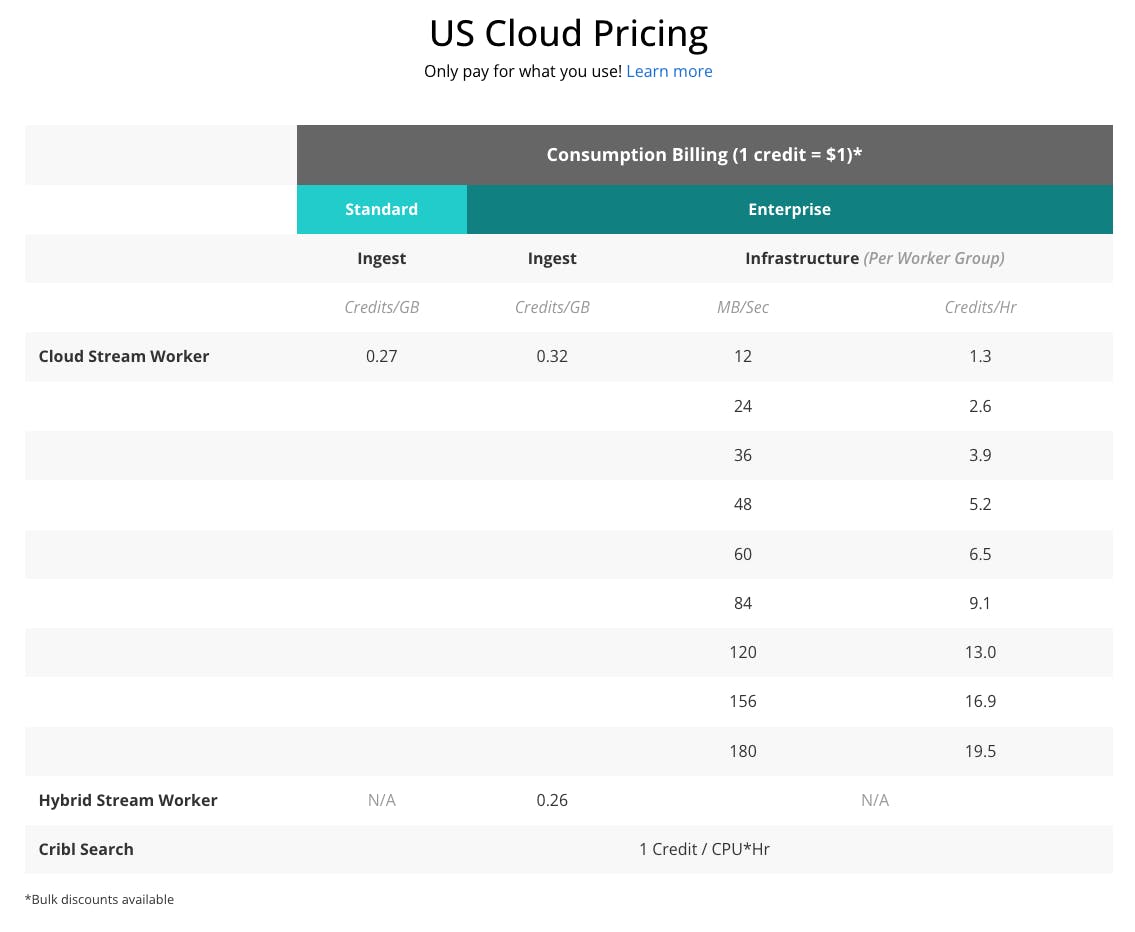
Cribl is a subscription SaaS company that prices based on the amount of data a customer needs to ingest and process.
There are two paid editions of Cribl—Standard and Enterprise. Standard offers up to 5TB per day in data volume, one worker group, 50 max worker processes, and limited support hours. Their Enterprise plan is fully unlimited on data volume, worker groups, max worker processes, fleets, and all major usage components. Support is available 24 hours a day, 7 days a week.
Standard and Enterprise differ slightly on their individual billing rates for ingest and infrastructure: on Standard, ingest costs $0.27 in credits per GB while it costs $0.32 in credits per GB on Enterprise.
Lastly, the Cribl Free plan allows teams to sign up and try the product with a limit of 1TB per day in data ingest and processing, but access to unlimited pipelines and routes and data sources.
Competition
Cribl operates in the observability and data infrastructure market, competing primarily with established data platform providers and emerging specialized solutions.
Traditional observability platforms
Major players like Splunk, Datadog, and Elastic dominate this space with end-to-end solutions for log management and analysis. These incumbents have responded to Cribl's emergence by developing their own pipeline tools - Splunk launched Ingest Actions while Datadog introduced Vector.dev. However, their usage-based pricing models remain a key vulnerability that Cribl exploits.
Data infrastructure providers
Companies like Snowflake and Databricks focus on general data analytics and warehousing. While they serve data teams broadly, they differ from Cribl's specialized focus on IT operations and security teams. Traditional data management companies like Commvault and Rubrik concentrate on backup and recovery rather than real-time observability.
Specialized data pipeline solutions
This emerging category includes vendors focusing on specific aspects of data routing and optimization. Companies like Vector and Logstash provide open-source alternatives for data collection and processing, though with less enterprise functionality than Cribl's suite. New entrants are also targeting specific use cases - for instance, companies building search capabilities to compete with Cribl Search or edge processing solutions to rival Cribl Edge.
The competitive landscape is evolving as enterprises seek solutions to manage growing data volumes while controlling costs. Cribl's vendor-neutral approach and focus on cost optimization through metadata reduction has helped it gain significant market share, particularly among price-sensitive large enterprises looking to reduce spending on incumbent platforms.
TAM
Cribl has tailwinds from explosive enterprise data growth (28% CAGR) and the increasing need for cost-effective data management solutions. The company has opportunities to expand beyond its initial observability pipeline market ($2B) into several adjacent markets.
Security and compliance data management
The security information and event management (SIEM) market represents a $10B opportunity where Cribl can leverage its existing capabilities. Their vendor-neutral approach allows them to help enterprises optimize security data storage while maintaining compliance requirements. The launch of Cribl Lake demonstrates their ability to execute on this expansion.
Application performance monitoring
The $10B APM market presents another significant growth vector. Cribl's ability to process and route telemetry data positions them to compete in this space. Their expansion from data routing to storage solutions mirrors successful vertical integration strategies seen in other markets.
Enterprise data lakes
With Cribl Lake, the company is moving into the broader enterprise data lake market. Their approach differs from traditional players like Snowflake and Databricks by focusing specifically on IT and security teams' needs. This positions them to capture a portion of enterprise data infrastructure spending, particularly as companies struggle with growing data volumes outpacing IT budgets.
Cloud services expansion
Currently at 30% cloud business, Cribl's planned expansion to 40-50% cloud adoption represents significant growth potential. Their multi-cloud strategy and integration with major providers like AWS, Azure, and Google Cloud creates opportunities to capture more enterprise spending as companies transition to cloud-based data management solutions.
Funding Rounds
|
|
|||||||||
|
|||||||||
|
|
|||||||||
|
|||||||||
|
|
|||||||||
|
|||||||||
|
|
|||||||||
|
|||||||||
|
|
|||||||||
|
|||||||||
|
|
|||||||||
|
|||||||||
| View the source Certificate of Incorporation copy. |
News
DISCLAIMERS
This report is for information purposes only and is not to be used or considered as an offer or the solicitation of an offer to sell or to buy or subscribe for securities or other financial instruments. Nothing in this report constitutes investment, legal, accounting or tax advice or a representation that any investment or strategy is suitable or appropriate to your individual circumstances or otherwise constitutes a personal trade recommendation to you.
This research report has been prepared solely by Sacra and should not be considered a product of any person or entity that makes such report available, if any.
Information and opinions presented in the sections of the report were obtained or derived from sources Sacra believes are reliable, but Sacra makes no representation as to their accuracy or completeness. Past performance should not be taken as an indication or guarantee of future performance, and no representation or warranty, express or implied, is made regarding future performance. Information, opinions and estimates contained in this report reflect a determination at its original date of publication by Sacra and are subject to change without notice.
Sacra accepts no liability for loss arising from the use of the material presented in this report, except that this exclusion of liability does not apply to the extent that liability arises under specific statutes or regulations applicable to Sacra. Sacra may have issued, and may in the future issue, other reports that are inconsistent with, and reach different conclusions from, the information presented in this report. Those reports reflect different assumptions, views and analytical methods of the analysts who prepared them and Sacra is under no obligation to ensure that such other reports are brought to the attention of any recipient of this report.
All rights reserved. All material presented in this report, unless specifically indicated otherwise is under copyright to Sacra. Sacra reserves any and all intellectual property rights in the report. All trademarks, service marks and logos used in this report are trademarks or service marks or registered trademarks or service marks of Sacra. Any modification, copying, displaying, distributing, transmitting, publishing, licensing, creating derivative works from, or selling any report is strictly prohibited. None of the material, nor its content, nor any copy of it, may be altered in any way, transmitted to, copied or distributed to any other party, without the prior express written permission of Sacra. Any unauthorized duplication, redistribution or disclosure of this report will result in prosecution.